nlp_with_transformers_visualizations
NLP with Transformers chapter 3: Transformer anatomy
In this chapter, we will dive deeper into the Transformers architecture, exploring the main building blocks of a transformer model. We will focus on constructing the attention mechanism and then integrate all the necessary components to make the encoder function. Additionally, we’ll highlight the key distinctions between the encoder and decoder modules.
Tighten your seatbelt, it’s time to explore the wonders of NLP✨.
The Transformer Architecture
The original form of transformer was initially based on the encoder-decoder architecture primarily used for translation tasks, However, this design faced challenges in effectively handling long sequences. This is where the attention mechanism comes into play.
The transformer consists of two main components :
Encoder:
convert an input sequence into a sequence of embeddings (hidden states).
Decoder:
uses its output and the encoder’s hidden states to iteratively generate the output sequence.
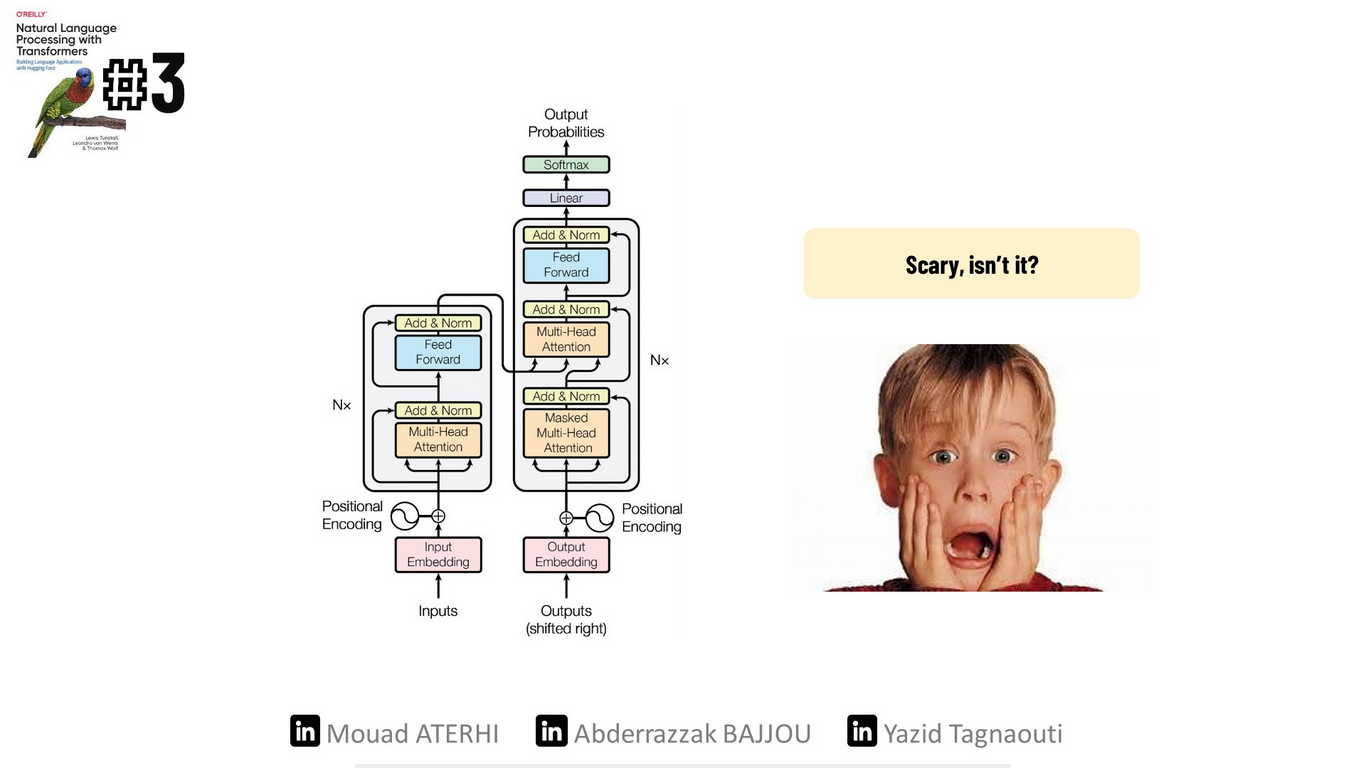
Scary, isn’t it🫣? Don’t worry. We’re here to make it simpler.
The Encoder
The transformer’s encoder is composed of many layers. In each layer, a sequence of embeddings is passed through two main components:
1) A multi-head self-attention layer
2) A fully connected feed-forward layer that is applied to each input embedding
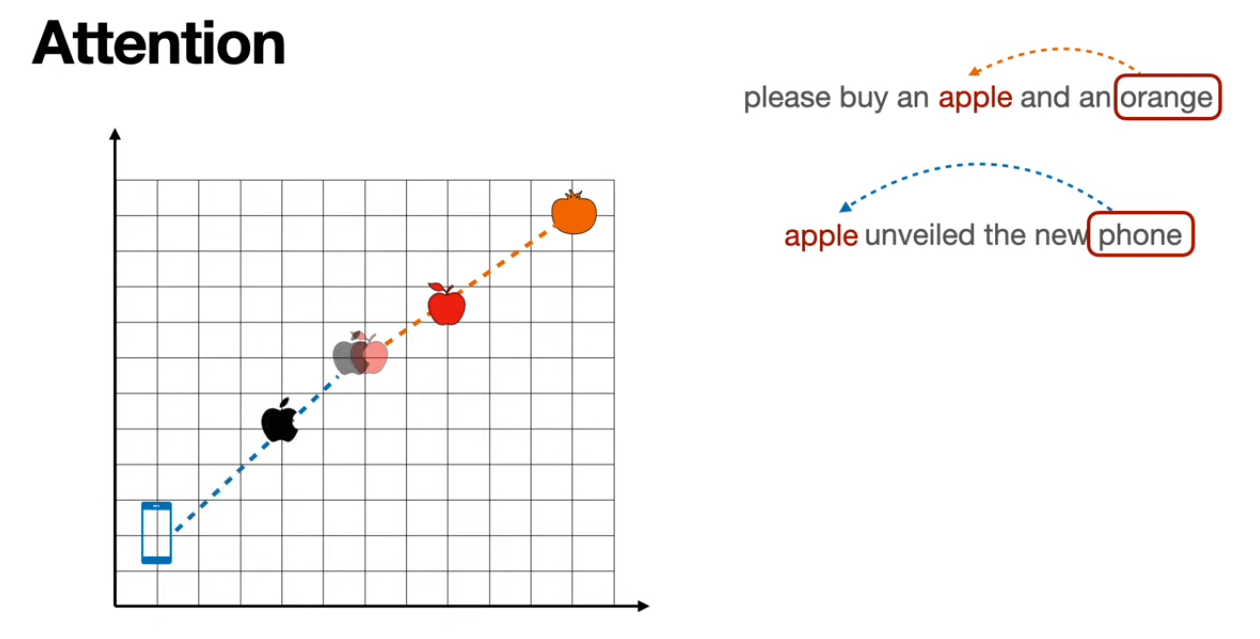
At the end of our encoder, we have output embeddings that maintain the same size as the inputs. They become more contextually aware. For example, if we refer to an “Apple iphone”, the word “Apple” will be updated at the end to be more “company-like” and less “fruit-like”.
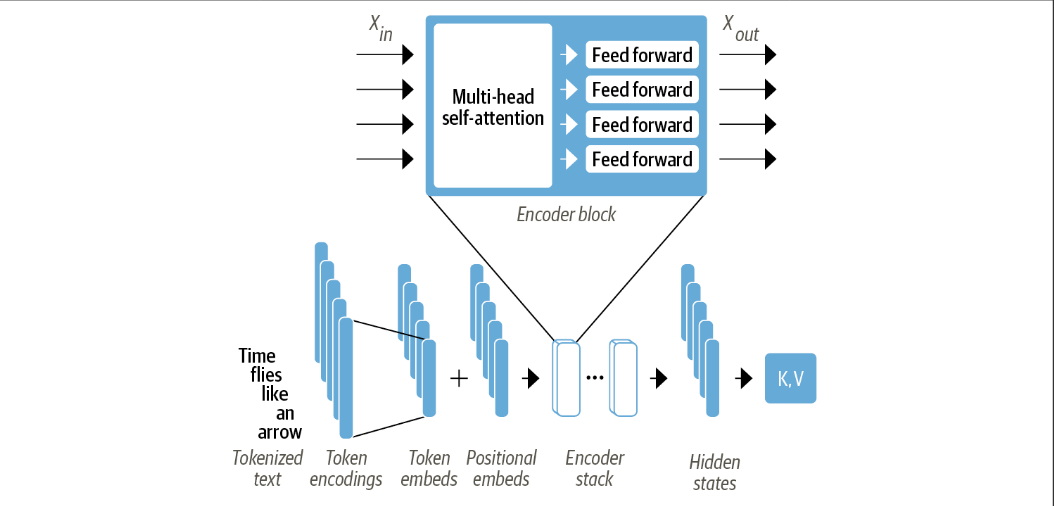 To gain a clear understanding of how it truly works, let’s begin with the first component.
To gain a clear understanding of how it truly works, let’s begin with the first component.
Word Embeddings
In Chapter 2, we learned that every word in our input sentence is tokenized, forming a tokens matrix of size (max_sentence_length, vocab_size). Next, we apply a pre-trained weighted matrix to the tokens matrix, transforming the tokenized text into vectors or token embeddings typically of size 768 or 512. Each dimension in these embeddings represents a distinct feature of the word, such as its fruitness.
The problem is that these new embedding vectors are completely invariant to the position of the word. Luckily, there is an easy trick to capture position information. Let’s take a look.
Positional Embeddings
Positional embeddings are based on a simple technique: we add to each token embedding a new vector position of equal size. This approach gives each word its positional information within the sentence.
To create these vectors, we use sine and cosine functions, as illustrated below, where ‘pos’ represents the position of the word in the sentence, ‘i’ indicate the index in the vector position, and ‘d_model’ represents the embedding dimension.
There are several reasons why this method is useful: first, the periodicity of the functions helps in capturing the word’s position; additionally, the output of sine and cosine falls between [-1,1], which is normalized. It won’t grow to unmanageable numbers during calculations; furthermore, no additional training is required, as a unique representation is generated for each position.
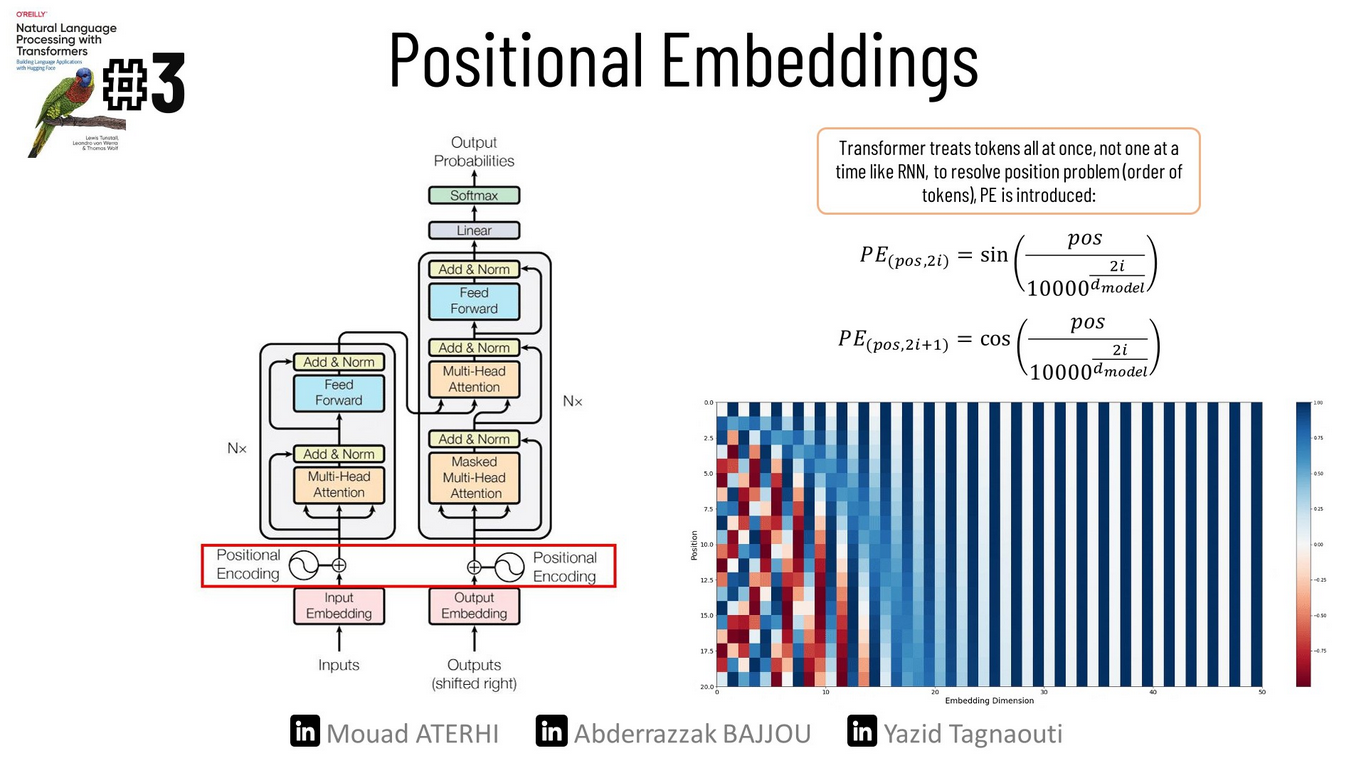
Now that we’ve encountered these concepts, we are ready to dive into the most important building block.
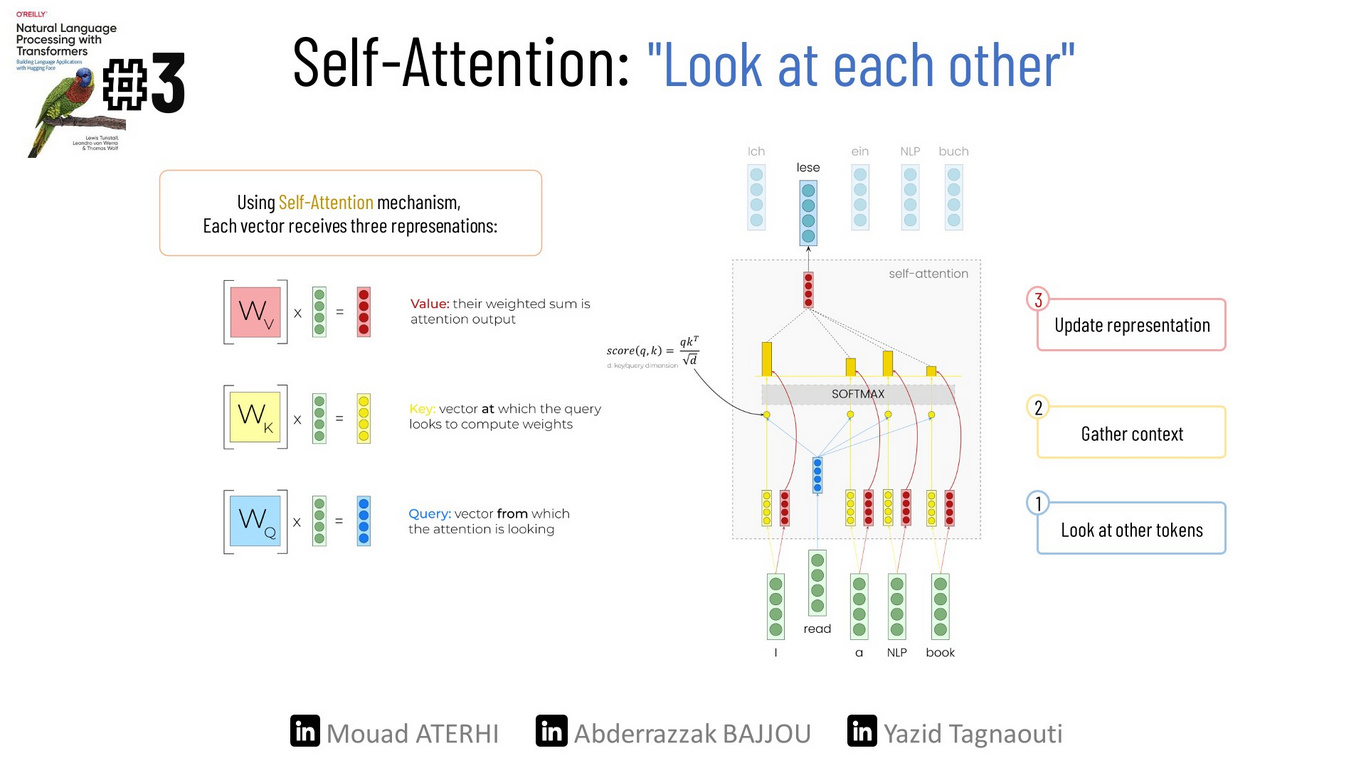
Self-attention
As we saw earlier, each token is individually represented by a vector of either 768 or 512 dimensions. The main idea behind self-attention is to use the entire sequence to compute a weighted average matrix that describes the relationships between each token embedding and the other token embeddings within the same sentence. As a result, we end up with embeddings that capture context more effectively.
To do so, we use a technique called:
the scaled dot product:
There are four main steps to implement this mechanism :
1 ) Project each token embedding into three vectors, called:
- query: represents the token from which the attention mechanism is getting the information, it’s used to compare against all the key vectors.
- key: tells the attention mechanism which parts of the sequence are important for understanding the query.
- value: holds the information (features) associated with each token in the sequence.
In the end, we put together all the queue vectors into one matrix, and we do the same for the key and value vectors, resulting in three distinct matrices.
2 ) Compute attention scores. we use the similarity function, which is the dot product of the Query and Key matrix. query and keys that are similar will have a large dot product,
3 ) To prevent dealing with large numbers, we normalize the variance of the attention scores by dividing them by the square root of the dimension of the keys SQRT(d_k), and then we apply a softmax function to convert the column values into a probability distribution.
4 ) Multiply the attention weights by the Value matrix to obtain updated embeddings.
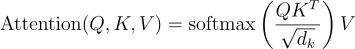
To make it clearer, let’s provide a simple example:
Let’s consider the following sentence: ‘I love Apple iPhones.’ We will represent it in a two-dimensional embedding space, where the first dimension represents the fruitiness of the word, and the second represents the technology.
| Fruitness | Technology | |
|---|---|---|
| I | 5 | 5 |
| Love | 7 | 2 |
| Apple | 11 | 9 |
| IPhones | 2 | 20 |
Let’s now calculate the attention matrix and focus only on the word “Apple”, which was initially associated more with fruits than technology.
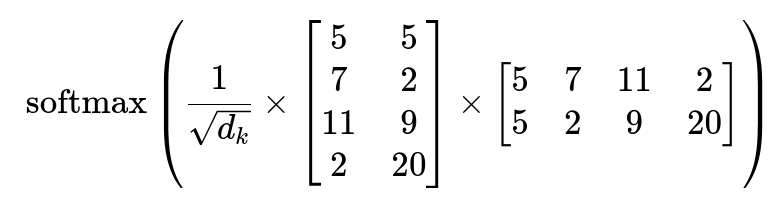
we got :

We can see that the word ‘Apple’ is more focused on the word ‘IPhones’ compared to the other words. Finally, let’s multiply our weighted matrix by the value matrix.
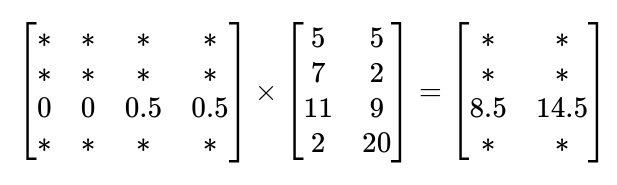
The Updated Apple Embedding : [Apple] = [8.5 14.5]
We can see how the embedding of the word ‘Apple’ becomes more company-like and less fruit-like.
Multi-headed attention
In our simple example, we only used the embeddings to compute the attention scores, but that’s far from the whole story. In practice, the self-attention layer applies three linear transformations to generate the query, key, and value vectors. Each of the three vectors is divided into n pieces, and each set of the new (q, k, and v) vectors are going to be part of creating a separate attention head. Finally, the outputs of these attention heads are concatenated to produce an output vector with more contextual awareness.
You may ask, why do we need more than one attention head? Well, the softmax of one head only focuses on one aspect of similarity. So, having several heads helps the model to focus on multiple aspects simultaneously (== similar to filters in CNN). In the end, we pass these new output vectors to a feed-forward layer so that they can communicate the learned information with each other.
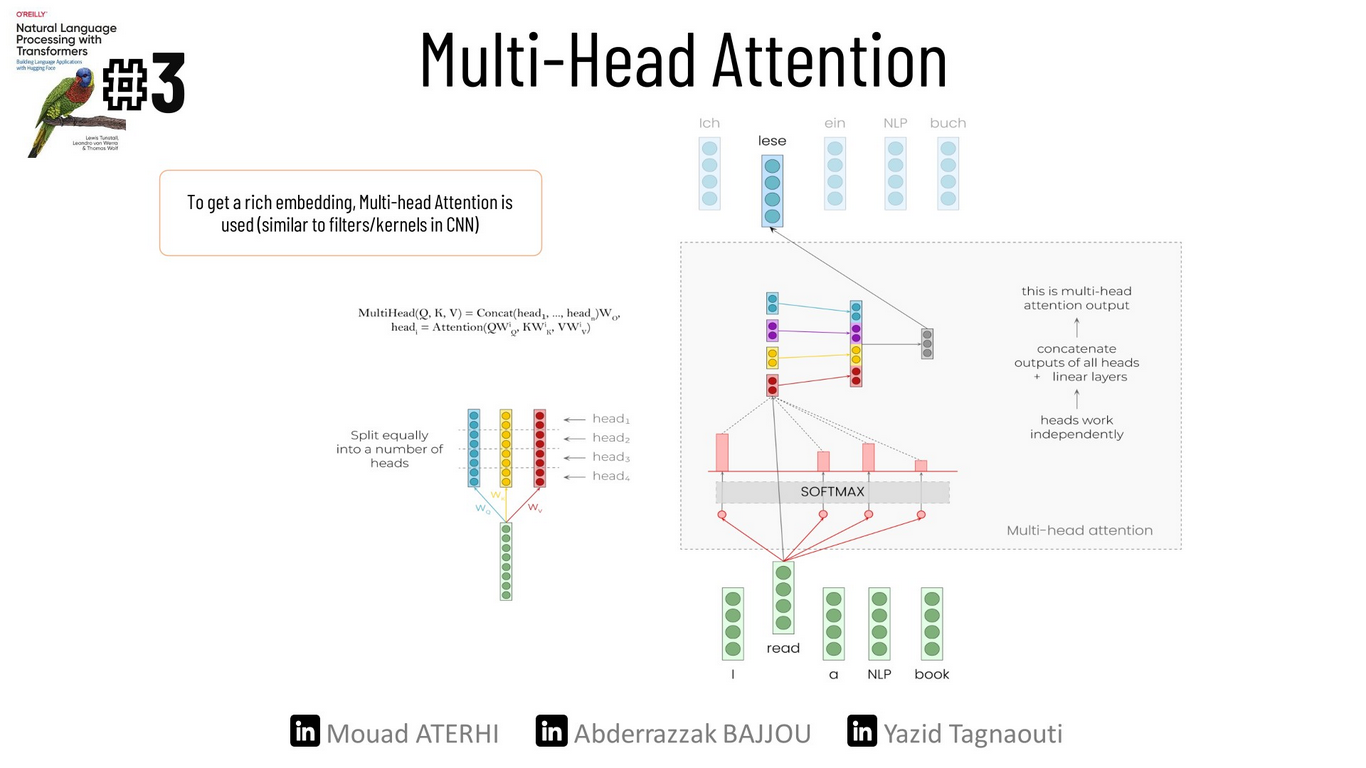
Now that we’ve finished with the encoder, let’s turn our focus to the decoder.
Decoder
The decoder continuously uses its previous output as input at each time step to generate the next word until the stop token “< eos >” is reached. As illustrated in the picture below, the main difference between the decoder and encoder is that the decoder has two attention sublayers:
The masked multi-head self-attention layer
It ensures that the tokens generated at each timestep are only based on the previous outputs. This method prevents the decoder from looking at future tokens. without this technique, the decoder can cheat during the training process by simply copying the target output.
To include masking into our attention matrix, just before applying the softmax, we simply add a square matrix with “-inf” above the diagonal and zeros everywhere else. We choose “-inf” because after applying the softmax, any value raised to “-inf” becomes 0 “ e^(-inf) = 0 “.
[0.7,0.1,0.1,0.1] [0,-inf,-inf,-inf] [0.7,-inf,-inf,-inf]
[0.1,0.3,0.6,0.1] + [0, 0,-inf, -inf] = [0.1, 0.3,-inf,-inf]
[0.1,0.6,0.1,0.2] [0, 0, 0, -inf] [0.1, 0.6, 0.1,-inf]
[0.4,0.1,0.2,0.3] [0, 0, 0, 0 ] [0.4, 0.1, 0.2, 0.3]
#Let's apply the softmax.
[0.7,-inf,-inf,-inf] [ 1 , 0, 0, 0 ]
softmax( [0.1, 0.3,-inf,-inf] ) = [0.2, 0.8, 0, 0 ]
[0.1, 0.6, 0.1,-inf] [0.2, 0.6, 0.2, 0 ]
[0.4, 0.1, 0.2, 0.3] [0.4, 0.1, 0.2, 0.3]
We can now clearly see how each word can only focus on the words generated before it.
The Encoder-decoder attention layer
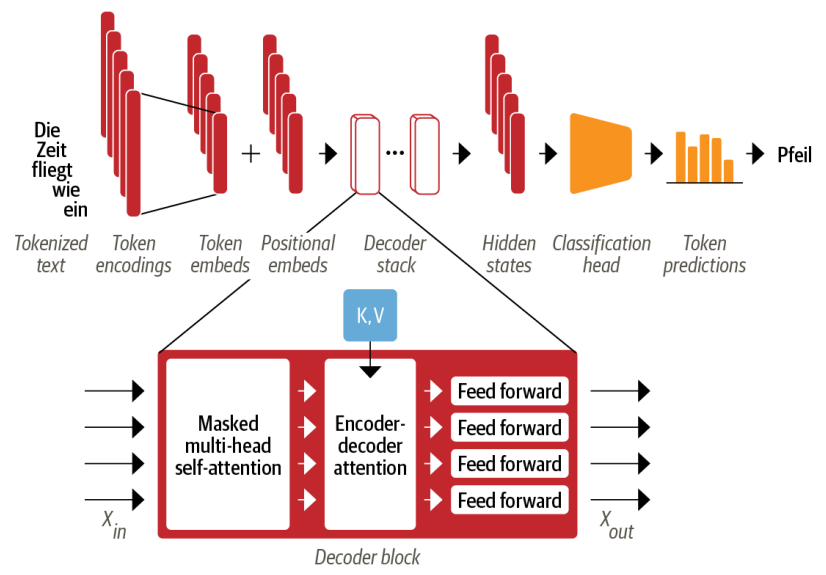
Performs the multi-head attention over the output Key and Value matrices of the encoder, with the Query matrix of the decoder. This way, the encoder-decoder attention layer learns how to relate tokens from two different sequences, such as two different languages in translation tasks. Then, we pass the output vectors to a feed-forward layer so that they can communicate the learned information with each other, just as we saw before.
After that, we pass our output vectors of size 768 through another feed-forward layer to expand them to the size of the output language vocabulary. Finally, we apply a softmax function to determine the most probable word.
Conclusion
🎉 Congratulations! Now, you have a deeper understanding of how transformers work💡. With their ability to attend to all positions in the input sequence simultaneously, transformers offer an alternative to recurrent neural networks, which often struggle with short term memory limitations. This makes transformers particularly advantageous when dealing with long sequences.
Additional code recources :
To get started and build your first transformer from scratch, I highly encourage you to take a look at this post. Happy coding🚀.